CLIP from OpenAI: what is it and how you can try it out yourself
By Vadim Frolov, Data Scientist at Inmeta
Neural networks (NN) and computer vision models in particular are known to perform well in specific tasks, but often fail to generalize to tasks they have not been trained on. A model that performs well on a food data may perform poorly on satellite images.
A new model from OpenAI named CLIP claims to close this gap by a large margin. The paper Open AI wrote presenting CLIP demonstrates how the model may be used on a various classification datasets in a zero-shot manner.
In this article, I will explain the key ideas of the model they proposed and show you the code to use it.
Intuition
In a typical classification scenario, one has a set of examples connected to a set of pre-defined categories. In such a set, the number of categories is fixed. If you train a model to distinguish between cats and dogs and then later decide to add a new class “bear”, then you will have to add example images with bears and train a new network!
However, if one were to train a network that connects an image to an arbitrary text, then you can utilize it with new classes simply by providing text description of that class. For this to work successfully, the network must learn good visual representations and good connections between visual cues and text.
How CLIP works
First, let us consider our problem scope. In order to connect images with text we need a dataset of image-text pairs. CLIP authors report that they assembled a dataset of 400 million (image, text) pairs from the Internet. The model will take an image as an input and predict text as an output.

There are different ways of representing text for prediction as shown on the figure below:

One can predict text with the correct word order, i.e. the classifier must output this is a photo of a cat. Or one can predict a label based on bag of words, i.e. the order of words is not important and if classifier predicts photo, cat, then it is correct. OpenAI suggests a further improvement upon the bag of words method and shows that CLIP is 4x more efficient in zero-shot ImageNet accuracy compared to previous methods.
CLIP achieves this by reframing the problem and using the contrastive pre-training. Instead of predicting label text, CLIP is training on predicting how likely this image is to correspond to that text.

Input images and texts are encoded, and their vector representations are used to build a similarity matrix (I*T is an inner product). Now, we know (during training) that the values on the diagonal represent correct classifications, so their similarity must be higher than those in the same row/column. This approach contrasts what we know go together (diagonal values) to what we know doesn’t go together (non-diagonal values). You can see that each row is a classification task: given an input image I, predict the text. Similarly, each column is a classification task: given an input text T, predict the image. During training, OpenAI used a very large size of mini-batches 32768 (N on the figure above).
During inference one takes a set of labels, creates texts based on labels and runs these texts through the text encoder. Text embeddings are later matched to image representation.
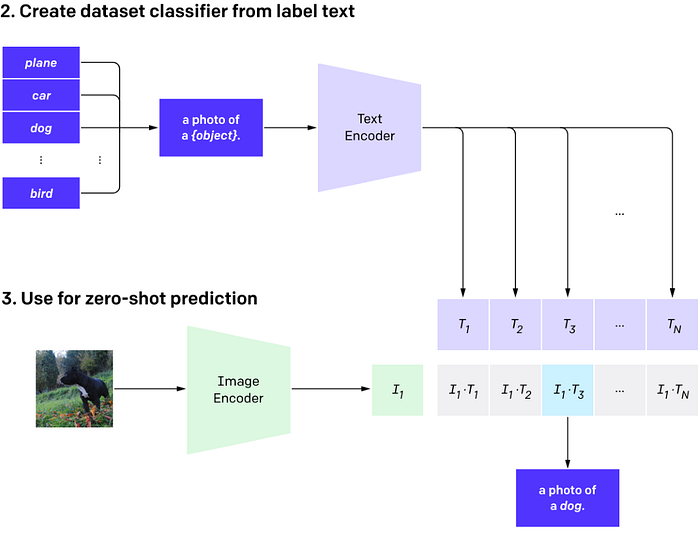
Classic classification training cares only about the predefined labels. If it is successful in findings dogs, then it doesn’t care if it is a photo or a sketch of a dog or a specific breed. Whereas CLIP training coupled with a large dataset makes the network learn various aspects of images and point attention to details.
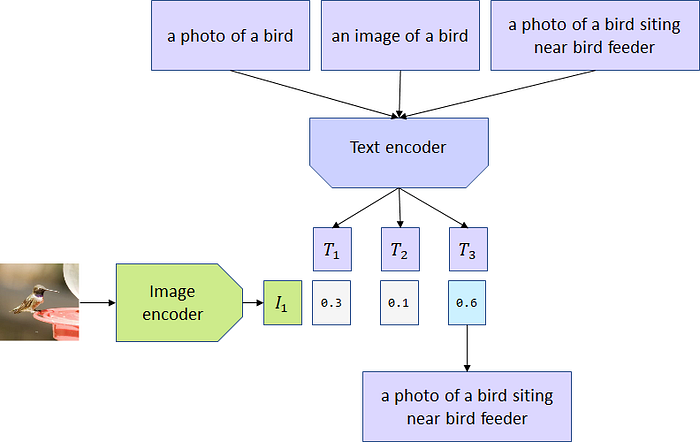
One detail that is worth mentioning is that CLIP is sensitive to words used for image descriptions. Texts “a photo of a bird”, “a photo of a bird siting near bird feeder”, or “an image of a bird” all produce different probability paired with the same image:
CLIP in a real project scenario
To illustrate the potential of CLIP, I would like to show a real project use case, based on one of the projects I worked on for a customer, an image similarity search engine. In this project, a user submits an image to model and as a result get a list of images that are visually similar to the query image. In our case, images being searched corresponded to pages of PDF documents and may contain individually or a mix of text, tables, embedded photos, empty pages, schemas, diagrams, and technical drawings. For the customer, the search return images of interest were technical drawings. Additionally, we also knew that what user searches would only be based on technical drawings.
The key characteristics of these images are that they contain a lot of small details that may be highly relevant for interpretation and that they may contain irrelevant patterns. Here are a couple of examples of technical drawings:
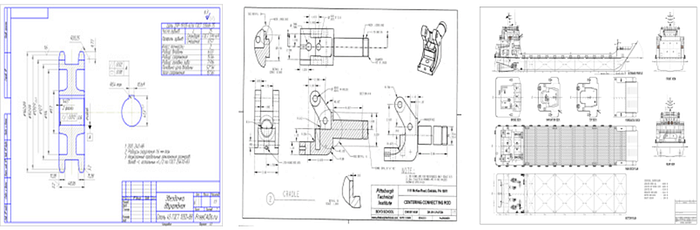
As always, the devil is in the details, and in this case these are things like the fact that each image contains textual information block in the bottom-right corner. For example, if there are a lot of technical drawings from Pittsburgh Technical Institute, then they all will have a very similar text block. Thus, a neural network may very quickly begin to anchor to that block.
The ResNet-18 model used in production was trained using SimCLR approach. SimCLR is a self-supervised contrastive learning method that allows to learn good visual representations without image labels. The model was trained on 100k images, ca. 50 % of which were technical drawings and the rest were all the other types of images.
Following this, I benchmarked CLIP against SimCLR for visual similarity search. I found that image features from a released CLIP-based model taken as zero-shot perform on pair with SimCLR-based model trained specifically for that data. This is truly amazing given that technical drawings are not the typical candidates for publicly available datasets. I can’t explain why CLIP is able to perform so well on technical drawings, might it be that examples of such drawings were part of the training dataset.
Another result shown here is that CLIP was not training with image similarity in mind. Yet it learned useful representations that may be used in image similarity scenarios.
CLIP current limitations
CLIP authors are open about its limitations. CLIP struggles on more abstract or systematic tasks such as counting the number of objects and on a more complex tasks such as estimating relative distances between objects. On such datasets, CLIP is only slightly better than random guessing. CLIP also struggles with very fine-grained classification, such as telling the difference between car models, variants of aircraft, or flower species.
CLIP model itself is data hungry and expensive to train. If pre-trained model doesn’t work well for you, it may be not feasible to train your own version.
While zero-shot CLIP tries to reformulate classification task, the principles are still the same. And although CLIP generalizes well to many image distributions, it still generalizes poorly to data that is truly out-of-distribution. One example of this was CLIP’s performance on MNIST dataset where CLIP zero-shot accuracy was 88 %. Logistic regression on raw pixels outperforms CLIP.
Ability to adapt to new datasets and classes is related to text encoder. It is thus limited to choosing from only those concepts known to the encoder. CLIP model trained with English texts will be of little help if used with texts in other languages.
Finally, CLIP’s classifiers can be sensitive to wording in label descriptions and may require trial and error to perform well.
Conclusions
CLIP training pushes the boundaries of traditional classifier a bit further, and the released pre-trained model allows one to perform various computer vision tasks (classification, image feature utilization) with good performance and without a need of a training set. As one of the pain points when working on real projects in data science is data scarcity, where there may be a lack of ground truth data or the amount of data is limited. As I show with an example, pre-trained CLIP-based model allows to kick-start such projects — thus this development is a welcomed addition to the Data Science toolbox.
I hope you enjoyed a presentation the key aspects of how CLIP works, and a high-level demonstration of what it can be used on.
If you have found it interesting, I highly recommend reading the original paper where authors run a lot of different experiments and show how CLIP performs zero-shot classification on a broad range of datasets.
How to try out CLIP yourself?
I’ve prepared a Colab notebook that shows how to interact with CLIP. There you will find not only the basic procedure, but also some insights into how text descriptions affect the outcome. Be sure to check it out!
That notebook uses 16 portrait photos of 3 people. I wanted to see if CLIP can discriminate these people. It certainly can! However, as CLIP authors point out in their paper, at the current state of development CLIP may be not the best candidate to perform such tasks, but it is a good way to see how the model works. Its capabilities are anyway look very interesting.
Acknowledgments
Big thanks to Maximilian Warner and Alexander Vaagan who helped preparing this post.
